I've created a toy Lakehouse Monitoring in Databricks setup to explore its features and capabilities. The goal is to understand how it works and what benefits it can bring. Here's an overview of what I cover in this post:
- How to Setup a toy Lakehouse Monitoring
- Dashboard
- Alerts
- Pricing
- My opinion on what I've seen
- Where's Databricks going?
- My2C
If you want to know more about what Databricks' Lakehouse Monitoring can do, I recommend checking out the official documentation. I have prepared a basic map of concepts that can help you get started.

How to Setup a toy Lakehouse Monitoring
Let's start by creating a table we can work with. It should be a time-series table
create table workspace.default.sales (
timestamp TIMESTAMP,
amount DOUBLE
)
I then create a basic notebook insert 1h of data.ipynb to fill table with data. Then, setup a job to run that notebook every hour.
I'll not add the code here because it is quite basic. It randomly adds records to the table with random values (within the time windown of the hour).
select * from workspace.default.sales
limit 10
| timestamp | amount |
|---|---|
| 2025-08-22T08:58:07.929Z | 22.570402586080093 |
| 2025-08-22T08:51:51.929Z | 20.713874028846366 |
| 2025-08-22T09:03:54.929Z | 21.97633174572098 |
| 2025-08-22T08:28:44.929Z | 27.94416169489641 |
| 2025-08-22T09:05:29.929Z | 21.307407500066127 |
| 2025-08-22T08:17:03.929Z | 22.37476392747984 |
| 2025-08-22T09:05:05.929Z | 26.446829879517953 |
| 2025-08-22T08:42:32.929Z | 27.86840740526422 |
| 2025-08-22T08:33:55.929Z | 27.236961570798947 |
| 2025-08-22T08:42:30.929Z | 25.395336538015343 |
Then, let's create the Monitor via Unity Catalog Explorer 👇
I set up the monitor as TimeSeries profile. I pointed out the timestamp column and a granularity of 1 hour. The schedule of the monitor is actually daily.
Below, a screenshot of the Unity Catalog Explorer page to create the Lakehouse Monitoring.
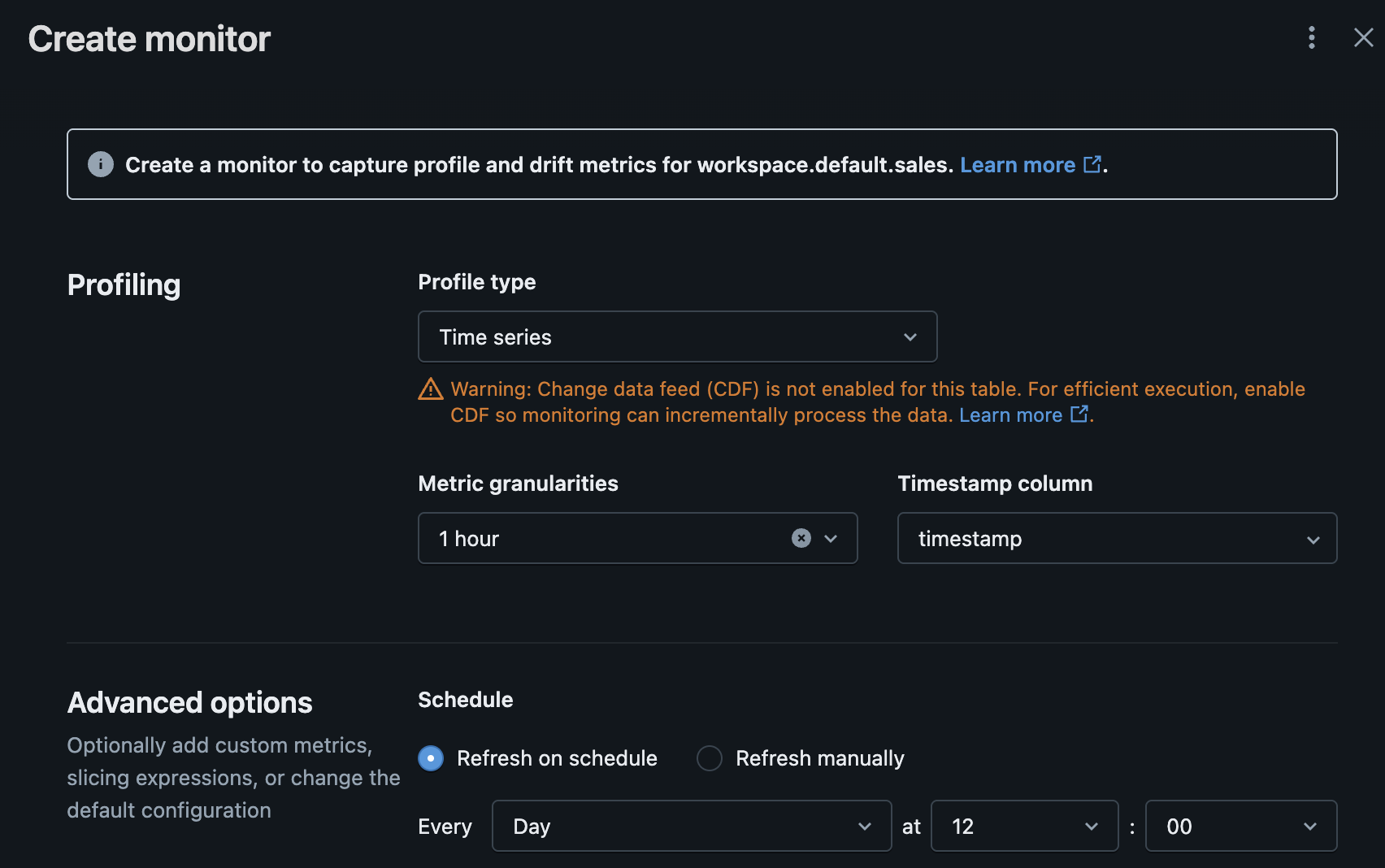
What happens after the creation of the Monitoring? By default, two new tables are created
<table_name>_profile_metrics<table_name>_drift_metrics
Let's inspect them
SHOW TABLES IN workspace.default;
| database | tableName | isTemporary |
|---|---|---|
| default | sales | false |
| default | sales_drift_metrics | false |
| default | sales_profile_metrics | false |
| _sqldf | true |
select * from workspace.default.sales_profile_metrics
| window | log_type | logging_table_commit_version | monitor_version | granularity | slice_key | slice_value | column_name | count | data_type | num_nulls | avg | min | max | stddev | num_zeros | num_nan | min_length | max_length | avg_length | non_null_columns | frequent_items | median | distinct_count | percent_nan | percent_null | percent_zeros | percent_distinct |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | :table | 1344 | null | null | null | null | null | null | null | null | null | null | null | List(timestamp, amount) | null | null | null | null | null | null | null |
| List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | amount | 1344 | double | 0 | 25.059042979855878 | 20.0007185120017 | 29.99500143216646 | 2.8817003714622857 | 0 | 0 | null | null | null | null | null | 25.133808306174608 | 1277 | 0.0 | 0.0 | 0.0 | 95.01488095238095 |
| List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | timestamp | 1344 | timestamp | 0 | null | 1.755850122929519E9 | 1.755853196019946E9 | null | null | null | null | null | null | null | null | 1.755851952929519E9 | 1161 | null | 0.0 | null | 86.38392857142857 |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | timestamp | 1192 | timestamp | 0 | null | 1.755853200929519E9 | 1.755856792565437E9 | null | null | null | null | null | null | null | null | 1.755854777019946E9 | 997 | null | 0.0 | null | 83.64093959731544 |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | :table | 1192 | null | null | null | null | null | null | null | null | null | null | null | List(timestamp, amount) | null | null | null | null | null | null | null |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | amount | 1192 | double | 0 | 24.847526487373074 | 20.01063581181195 | 29.99539398790598 | 2.8880160456500867 | 0 | 0 | null | null | null | null | null | 24.694267025212234 | 1192 | 0.0 | 0.0 | 0.0 | 100.0 |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | amount | 941 | double | 0 | 24.969054277784952 | 20.015936515703217 | 29.981071930502402 | 2.846773237150427 | 0 | 0 | null | null | null | null | null | 24.969920953185955 | 925 | 0.0 | 0.0 | 0.0 | 98.29968119022317 |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | timestamp | 941 | timestamp | 0 | null | 1.755856803565437E9 | 1.755860399121952E9 | null | null | null | null | null | null | null | null | 1.755858763121952E9 | 857 | null | 0.0 | null | 91.07332624867162 |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | :table | 941 | null | null | null | null | null | null | null | null | null | null | null | List(timestamp, amount) | null | null | null | null | null | null | null |
| List(2025-08-22T11:00:00.000Z, 2025-08-22T12:00:00.000Z) | INPUT | 26 | 0 | 1 hour | null | null | :table | 995 | null | null | null | null | null | null | null | null | null | null | null | List(timestamp, amount) | null | null | null | null | null | null | null |
The profile table has a row for each pair
window(the beginning and end of every hour)column_nameevery column of the table. In addition, it adds a special row:tableto compute the table-level profile.
Optionally, it can slice on column values when specified at the time of the creation of the Monitor
For each row, it computes a bunch of statistics like avg, quantiles, min, max, etc. (when applicable, eg for float columns).
select * from workspace.default.sales_drift_metrics
| window | granularity | monitor_version | slice_key | slice_value | column_name | data_type | window_cmp | drift_type | count_delta | avg_delta | percent_null_delta | percent_zeros_delta | percent_distinct_delta | non_null_columns_delta | js_distance | ks_test | wasserstein_distance | population_stability_index | chi_squared_test | tv_distance | l_infinity_distance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| List(2025-08-22T11:00:00.000Z, 2025-08-22T12:00:00.000Z) | 1 hour | 0 | null | null | :table | null | List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | CONSECUTIVE | -418 | null | null | null | null | List(0, 0) | null | null | null | null | null | null | null |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | 1 hour | 0 | null | null | :table | null | List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | CONSECUTIVE | -152 | null | null | null | null | List(0, 0) | null | null | null | null | null | null | null |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | 1 hour | 0 | null | null | :table | null | List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | CONSECUTIVE | -251 | null | null | null | null | List(0, 0) | null | null | null | null | null | null | null |
| List(2025-08-22T11:00:00.000Z, 2025-08-22T12:00:00.000Z) | 1 hour | 0 | null | null | timestamp | timestamp | List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | CONSECUTIVE | -418 | null | 0.0 | null | -5.604875005841791 | null | null | null | null | null | null | null | null |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | 1 hour | 0 | null | null | timestamp | timestamp | List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | CONSECUTIVE | -152 | null | 0.0 | null | -2.742988974113132 | null | null | null | null | null | null | null | null |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | 1 hour | 0 | null | null | timestamp | timestamp | List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | CONSECUTIVE | -251 | null | 0.0 | null | 7.4323866513561825 | null | null | null | null | null | null | null | null |
| List(2025-08-22T11:00:00.000Z, 2025-08-22T12:00:00.000Z) | 1 hour | 0 | null | null | amount | double | List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | CONSECUTIVE | -418 | 0.013276990751066364 | 0.0 | 0.0 | -0.21172707932451829 | null | null | List(0.049, 0.3829208808885818) | 0.16058939377867895 | 0.028216393260236203 | null | null | null |
| List(2025-08-22T10:00:00.000Z, 2025-08-22T11:00:00.000Z) | 1 hour | 0 | null | null | amount | double | List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | CONSECUTIVE | -251 | 0.12152779041187856 | 0.0 | 0.0 | -1.7003188097768316 | null | null | List(0.038, 0.4228041687817168) | 0.14481617304902772 | 0.021676869284417942 | null | null | null |
| List(2025-08-22T09:00:00.000Z, 2025-08-22T10:00:00.000Z) | 1 hour | 0 | null | null | amount | double | List(2025-08-22T08:00:00.000Z, 2025-08-22T09:00:00.000Z) | CONSECUTIVE | -152 | -0.21151649248280435 | 0.0 | 0.0 | 4.985119047619051 | null | null | List(0.062, 0.014853915612309707) | 0.21231645982023184 | 0.022438267042335924 | null | null | null |
The drift table is similar to the profile table. The drift table has a row for each pair
window(the beginning and end of every hour)column_nameevery column of the table. In addition, it adds a special row:tableto compute the table-level profile.
In addition, it has the window_cmp, where cmp stands for compare. All the statistics are compared against another window (the previous one). There are various statistics like
count_deltaks_test, in statistics, the Kolmogorov–Smirnov can be used to test whether two samples came from the same distribution
Dashboard
Lakehouse Monitoring creates also a dashboard automatically that displays the data in these profile and drift tables.
😓 However, I find this dashboard too crowded and not ready to use. You need to work on it to customize it by yourself.
Alerts
Monitor alerts are created and used the same way as other Databricks SQL alerts. You create a Databricks SQL query on the monitor profile metrics table or drift metrics table. You then create a Databricks SQL alert for this query.
Pricing
Lakehouse Monitoring is billed under a serverless jobs SKU. You can monitor its usage via system.billing.usage table or via the Usage dashboard at Account console.
You need to pay attention. I expect that the costs may rise for columns with high number of columns if you don't finetune the monitor.
SELECT usage_date, sum(usage_quantity) as dbus
FROM system.billing.usage
WHERE
usage_date >= DATE_SUB(current_date(), 30) AND
sku_name like "%JOBS_SERVERLESS%" AND
custom_tags["LakehouseMonitoring"] = "true"
GROUP BY usage_date
ORDER BY usage_date DESC
| usage_date | dbus |
|---|---|
| 2025-08-22 | 1.852757467777777736 |
My opinion on what I've seen
Lakehouse monitoring is all about these two profile and drift tables. It is a kind of brute force approach that runs standardized monitoring over the specified table and stores the output in the profiling tables. Is it convenient? It depends on what you're looking for. It is not a free lunch.
Pros 🟢
- It takes little effort to setup. By default common controls are applied to all columns in the monitored table.
- Most common monitoring scenarios are covered by
TimeSeriesprofile or bySnapshotprofile (I left apart the inference-ML for the sake of simplicity). The setup time is shorter when compared to anything made by yourself. - You have a framework ready to use. You save the time required designing it, and you avoid reinventing the wheel. You can focus on your business needs rather than on data engineering stuff.
- I like the simple but effective design of the drift metric table and of the windowing. Making something like this by yourself will probably let you hit against some hidden edge-case (like anytime you work with time and dates).
Cons 🔴
- Once the metrics are computed in the profile and drift tables, only half of the job is done. You still have to decide what to monitor and how to do it. You're probably not interested in monitor any single column in any row of the metric tables (otherwise you may alerted by too many false alarms). A finetuning of the actual alerts is still required, and it is not coming for free.
- You can't know in advance the overall cost of the monitoring. You need to try with a realistic (production-alike) scenario and monitor soon how much you're paying. I expect it to depend mainly on
- the data volume
- the columns in the table
- the frequency of the controls
Where's Databricks going?
In addition to Lakehouse Monitoring, Databricks has released a feature (in Beta) of data quality monitoring. This new monitoring
- is quicker to setup. It is toggle on an entire Schema and monitors all the tables in the schema.
- monitors only simple freshness and completeness quality controls
- has no parametrization
- still needs alerts to be set manually
I made a short recap here.
| Feature | Lakehouse Monitoring | Data Quality Monitoring (Beta) |
|---|---|---|
| Scope | Table. It is set at table level. It monitors the table and its columns. | Schema. It is set at schema level and monitors all tables in such schema. |
| Setup | Choose the profile, eventual slicing, window and frequency. | On-off on the schema. |
| What is monitored | Various statistics as snapshot, time series, and inference. | Freshness (is data recent?) and completeness (is the volume as expected?) |
| Customization | Limited | No |
| Alert | To be set manually on the output table. | To be set manually on the output table. |
My2C
🟢 I think Databricks is going in the right direction. Fast adoption of basic quality controls. Avoid the "didn't notice data is old in production" moments with little effort.
🔴 The alerting setup is still quite SQL-based and there is some trial-and-error around it. I would expect that a basic alert should be enabled by default.